ismir25_rach3midi_supp
Annotation File 2
- Filename: 2024-08-27_18-16_03_ponce_20Can-part2_annot.mid
- Download: MIDI
- Groups: 6
- Description: This is a longer example of an intermediate level repertoire with some overlaps between groups, where some groups are subsets of others. There are several note mistakes and note repetitions. The most challenging aspect are compositional variations between intervals of the same group, where the right hand is the same but the left hand is arranged differently. Furthermore, some groups have 2 related intervals only. It is constructed from a rehearsal of 20 Canciones (piezas faciles) by Manuel Ponce.
Visual Overview
| Group 1 | Group 2 |
|---|---|
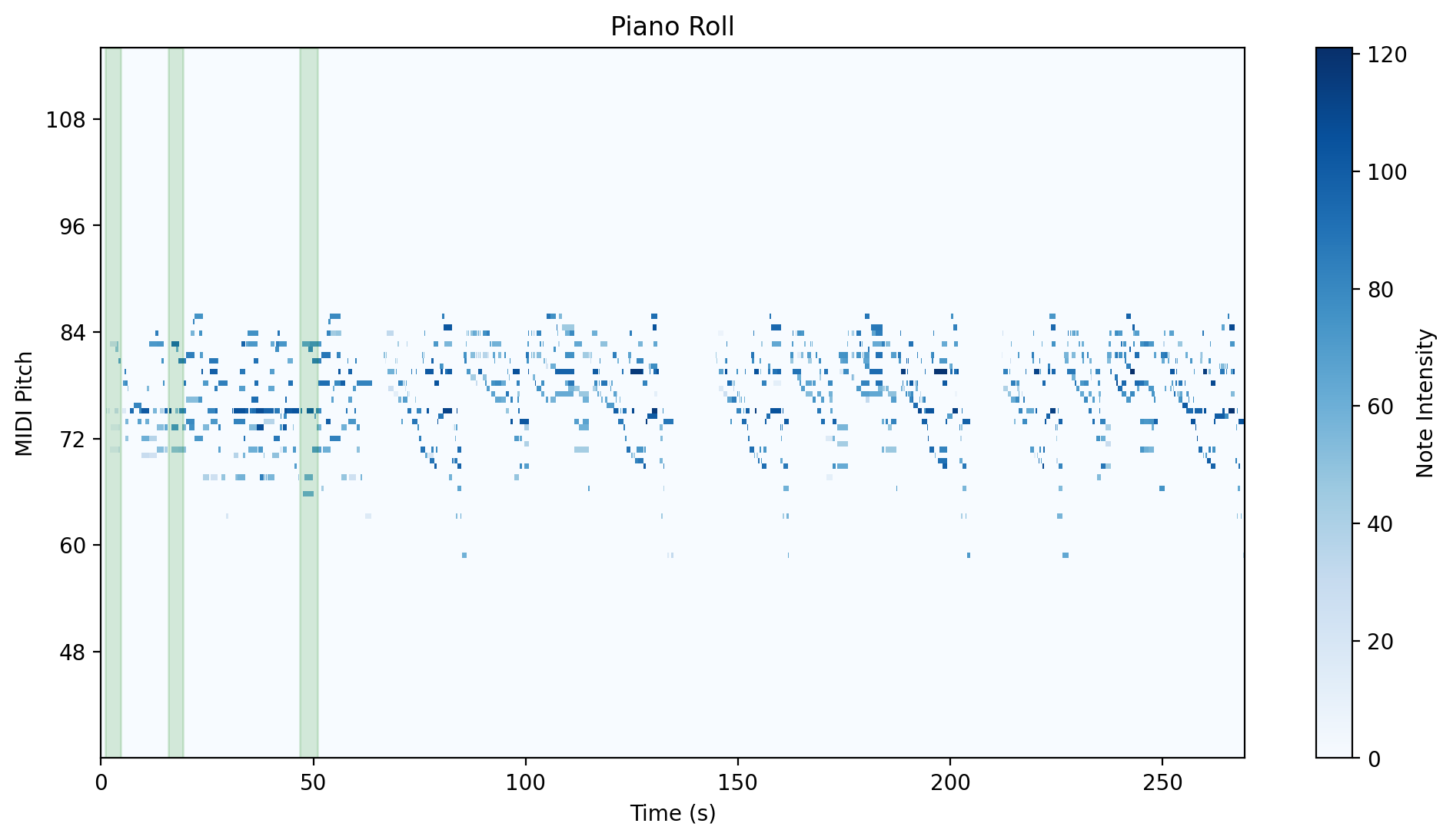 |
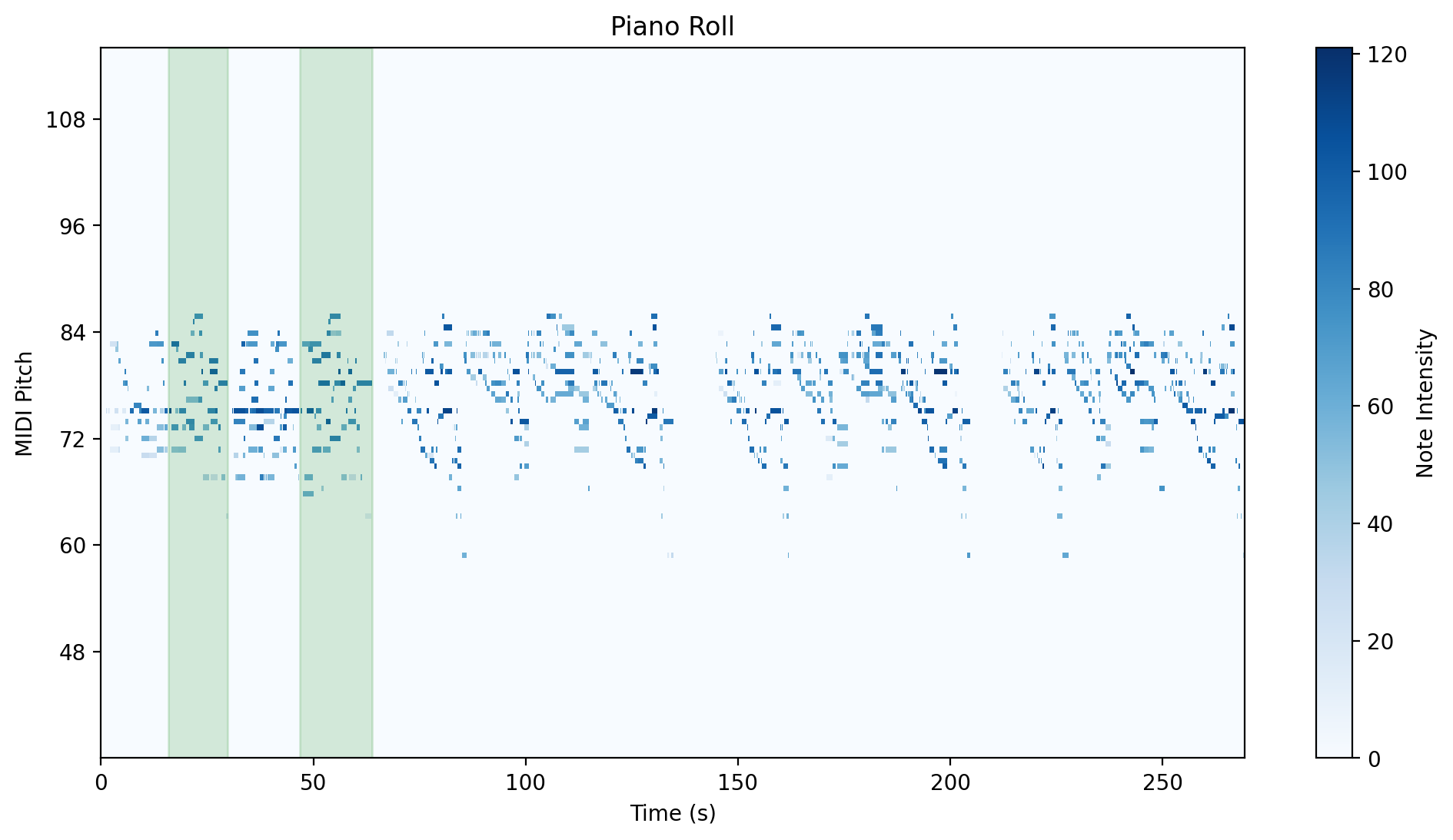 |
| Group 3 | Group 4 |
|---|---|
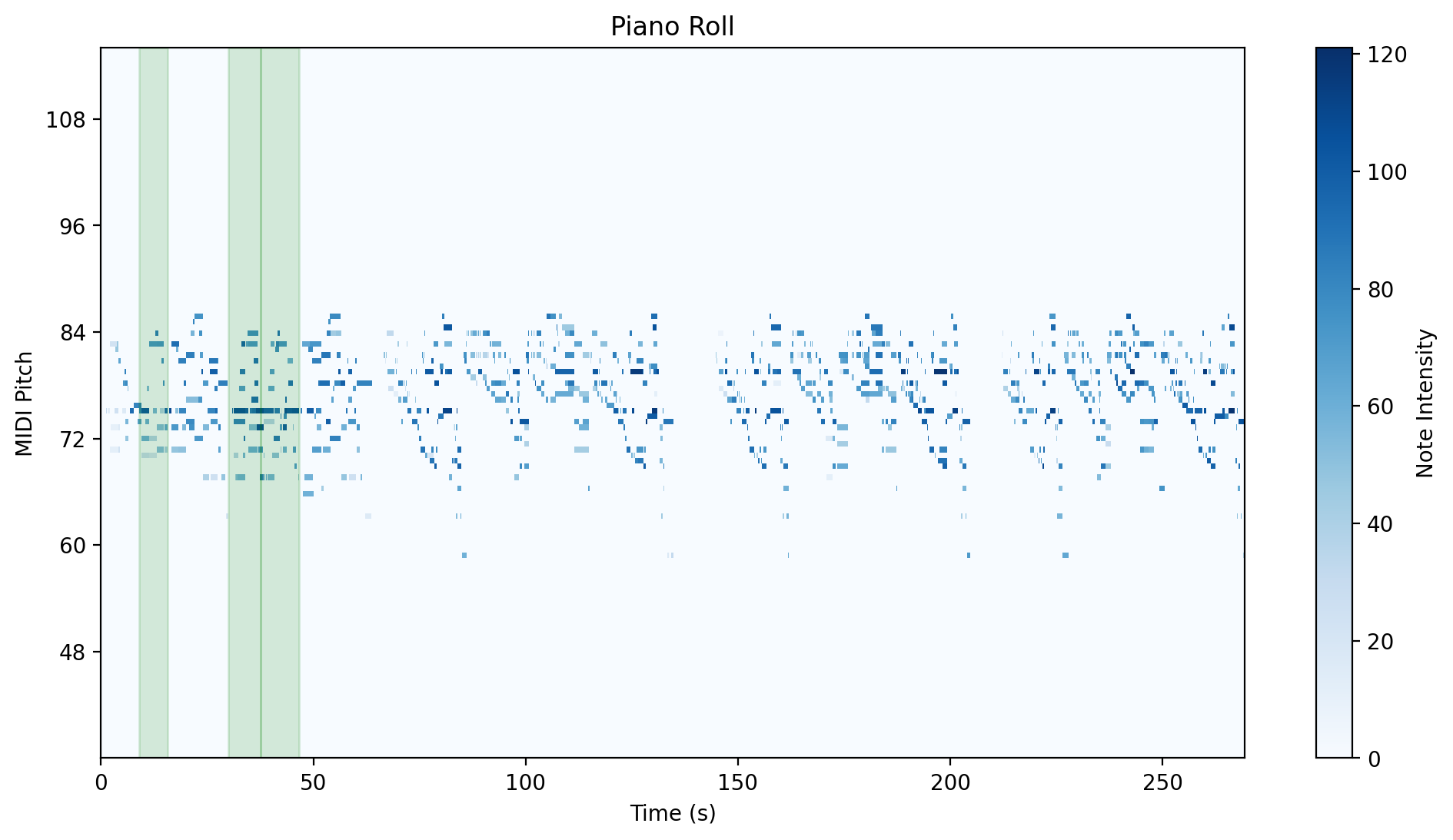 |
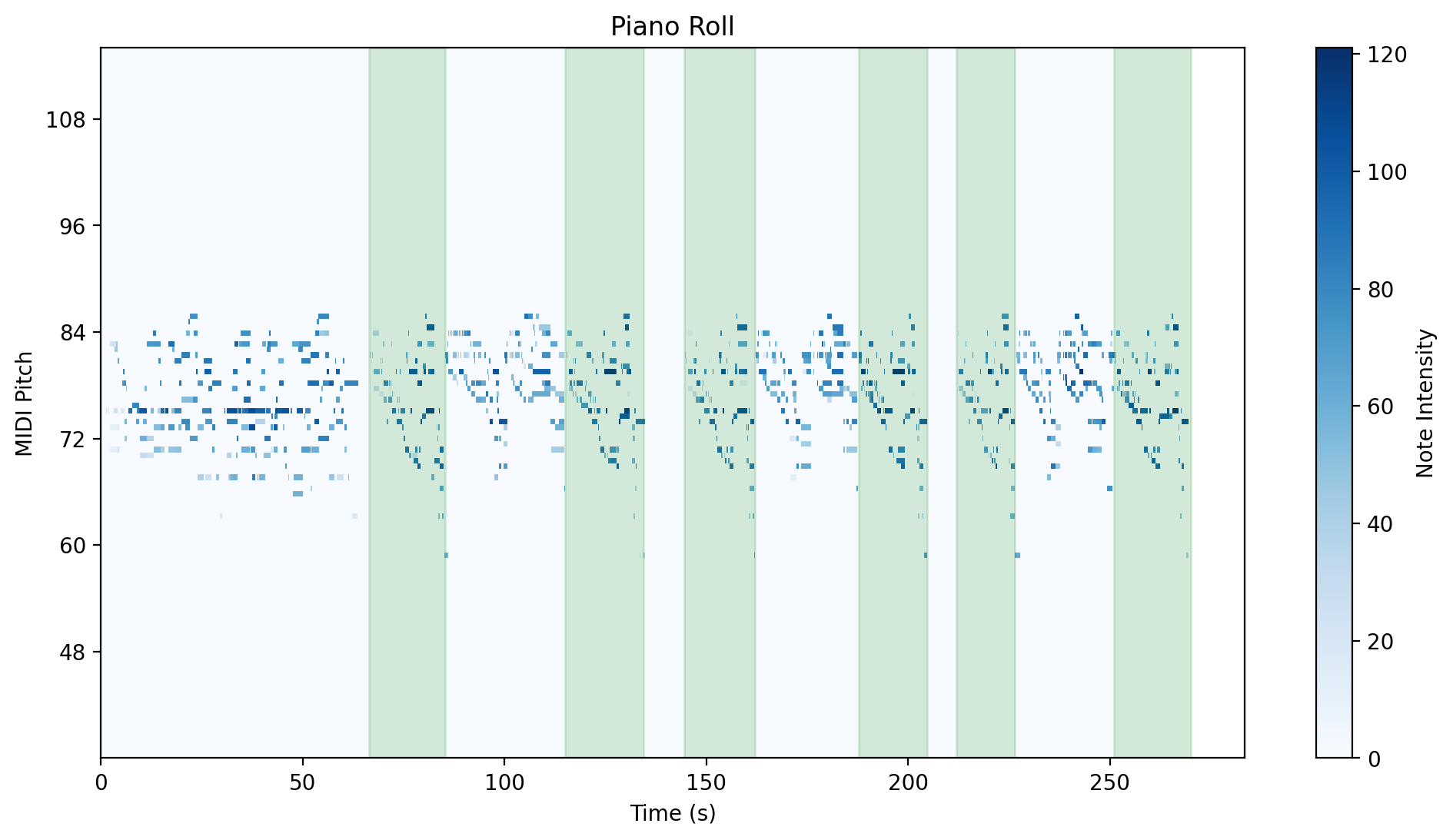 |
| Group 5 | Group 6 |
|---|---|
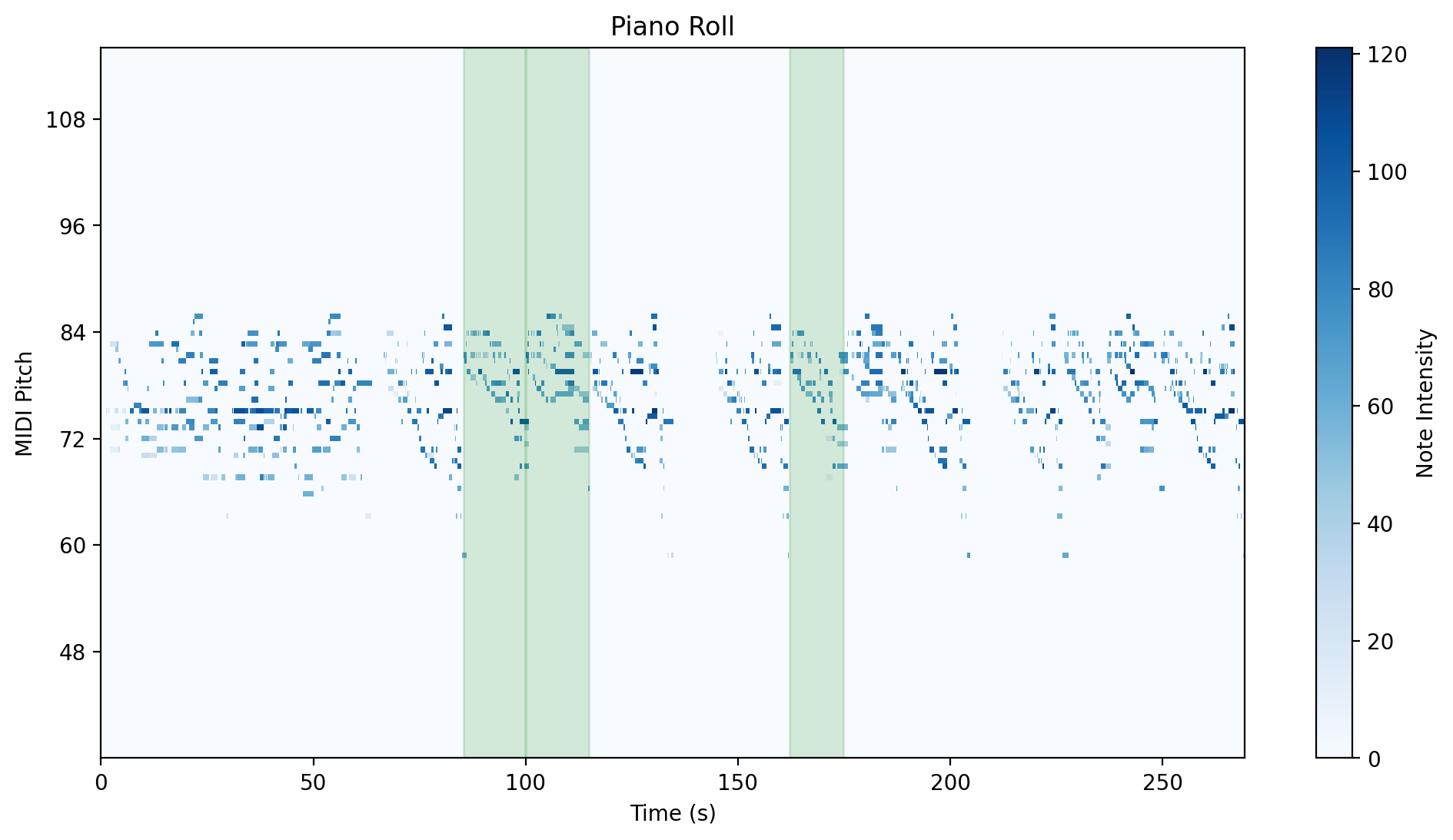 |
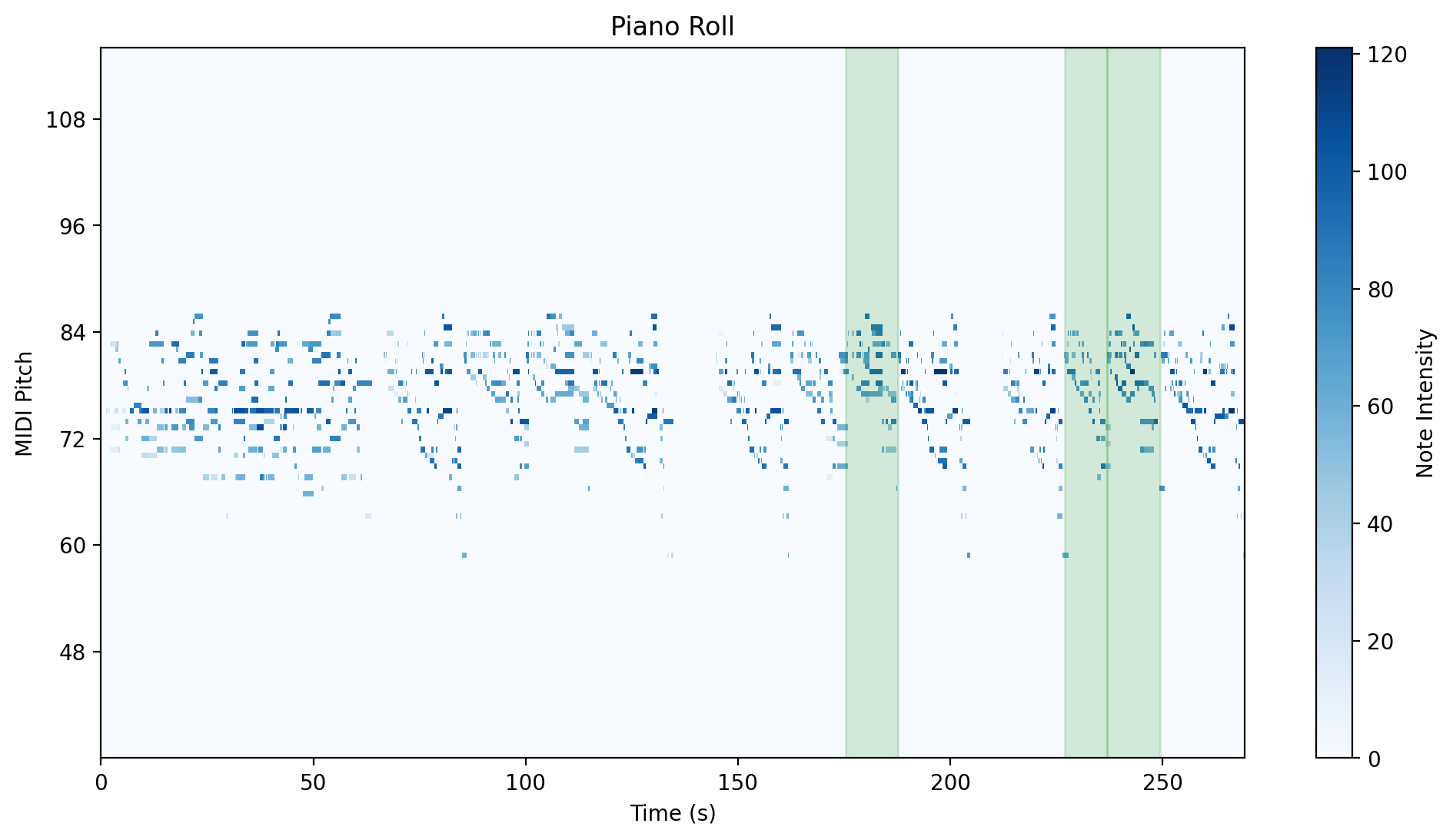 |
Challenges per group
- Group 1: The intervals are around 7 bins long,
- so despite occuring as a diagonal without interruptions, the group’s first interval pair would be undetected unless the minimum_length value is set to be very low.
- Its second interval pair would also not result in a diagonal due to the latter interval being a variation with a different left hand.
-
Group 2: this group relates intervals that are based on variants. When this happens, then even in the case of no extra or missing notes, the intervals belonging to a variant will include a different number of bins than those of the other.
-
Group 3: challenges are similar to group 2
- Groups 4, 5, and 6: The intervals are longer and they are not variants; the differences between them are due to rehearsal elements.
A closer look at the similarity matrixes between intervals of a group can demonstrate the above traits.
| Group 2 Example showing diagonal shifting due to compositional variations | Group 4 Example showing relatively long diagonals with some gaps and a shift towards the end |
|---|---|
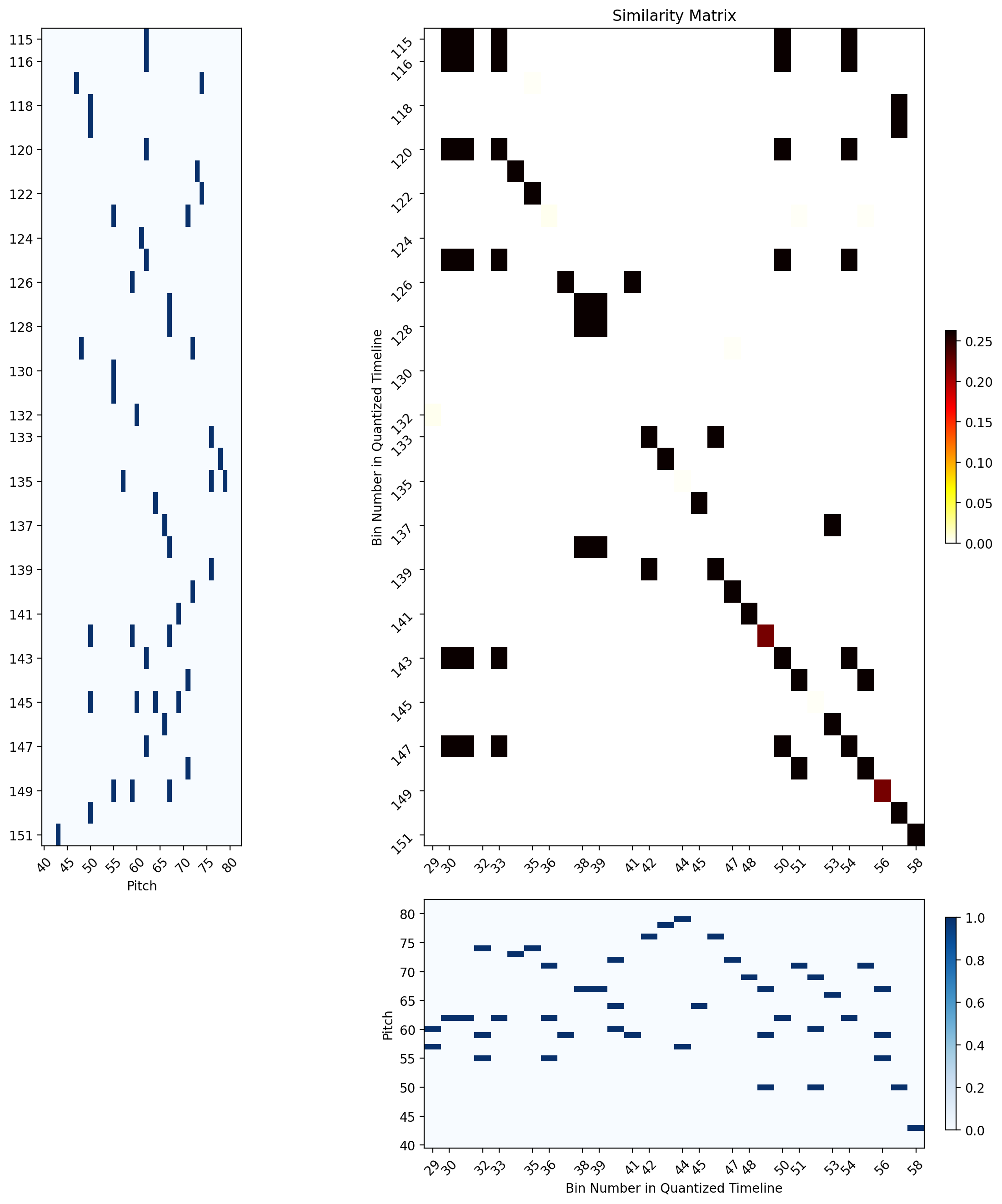 |
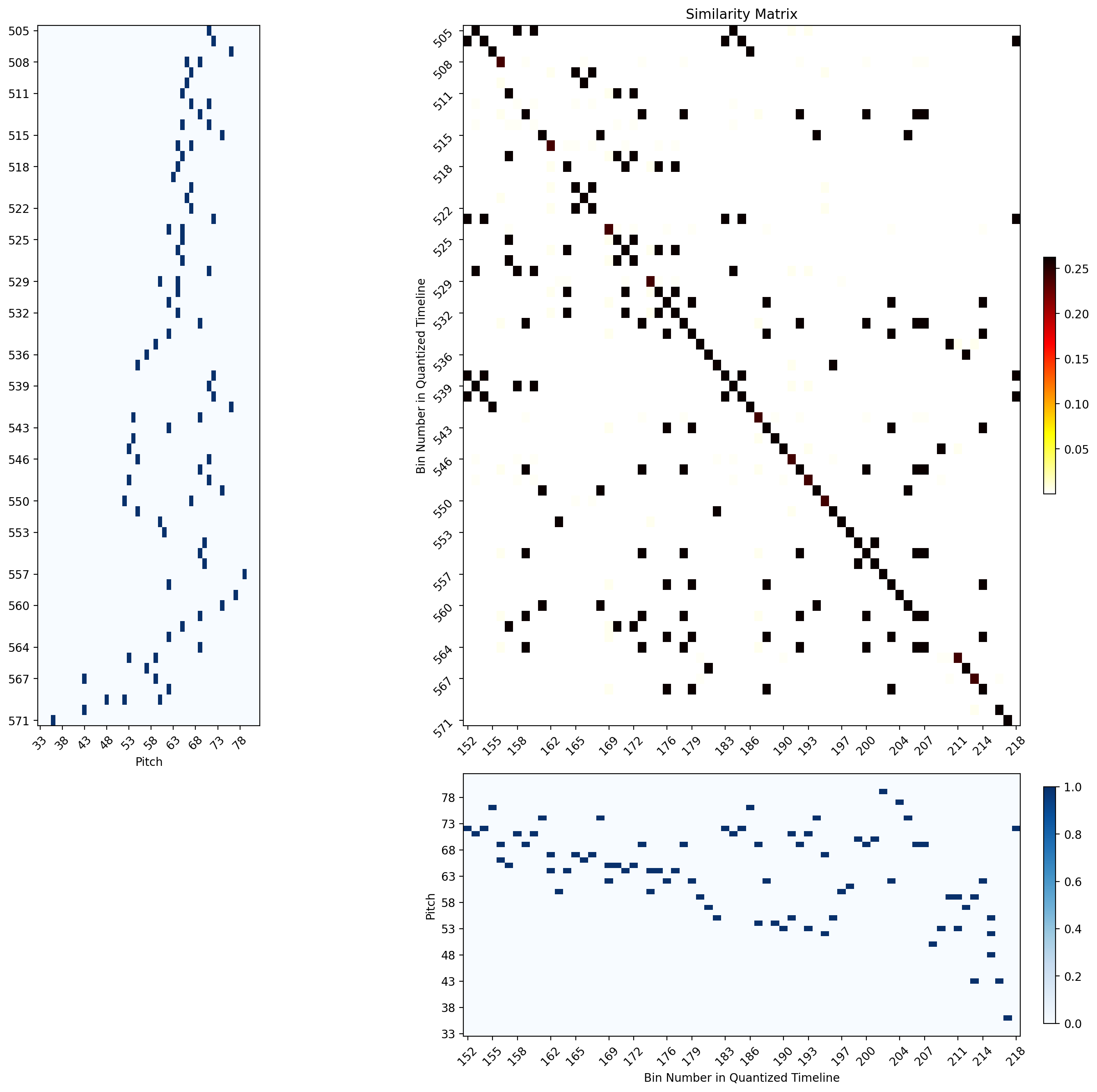 |
| Group 5 example | Group6 Example |
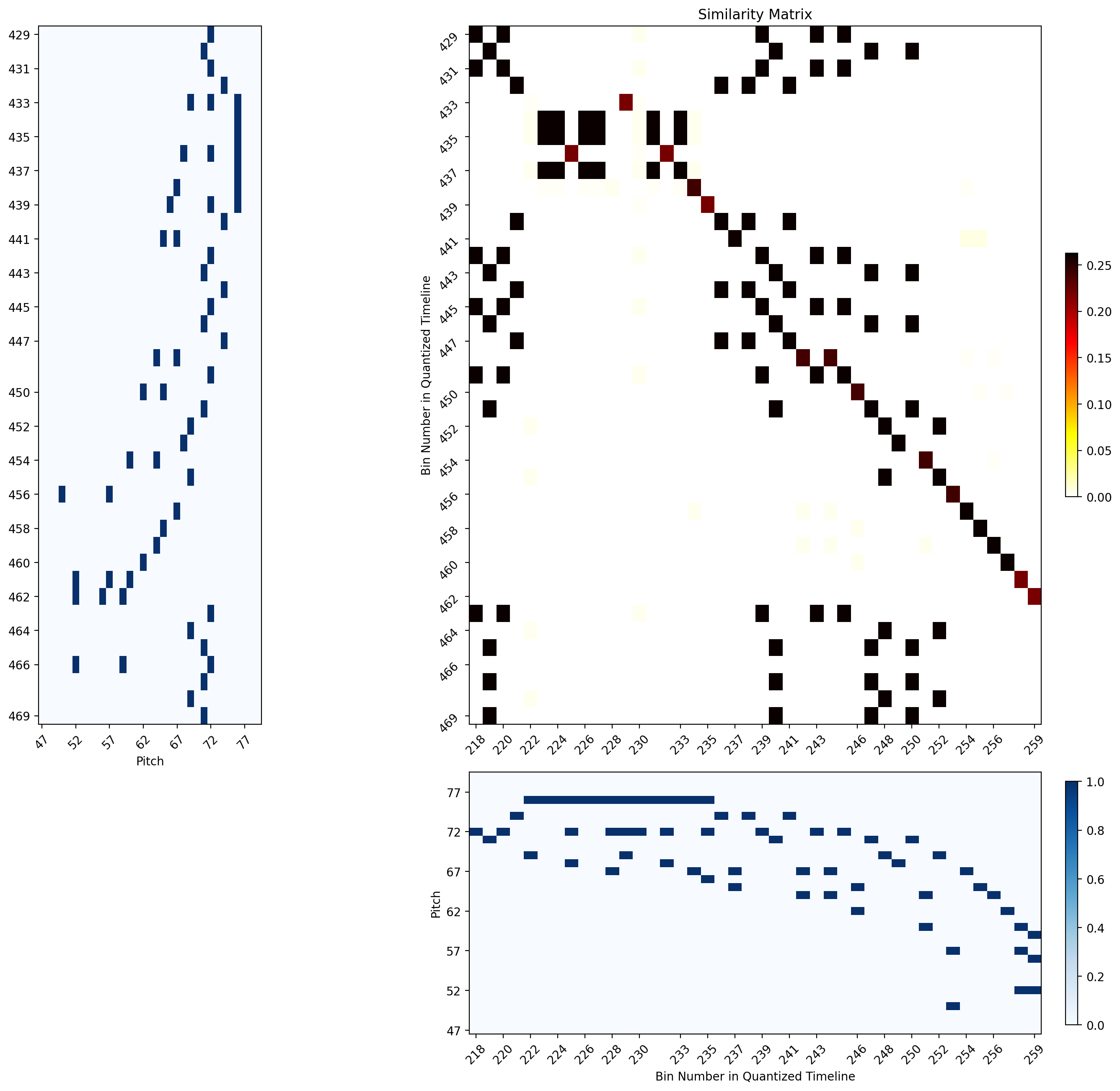 |
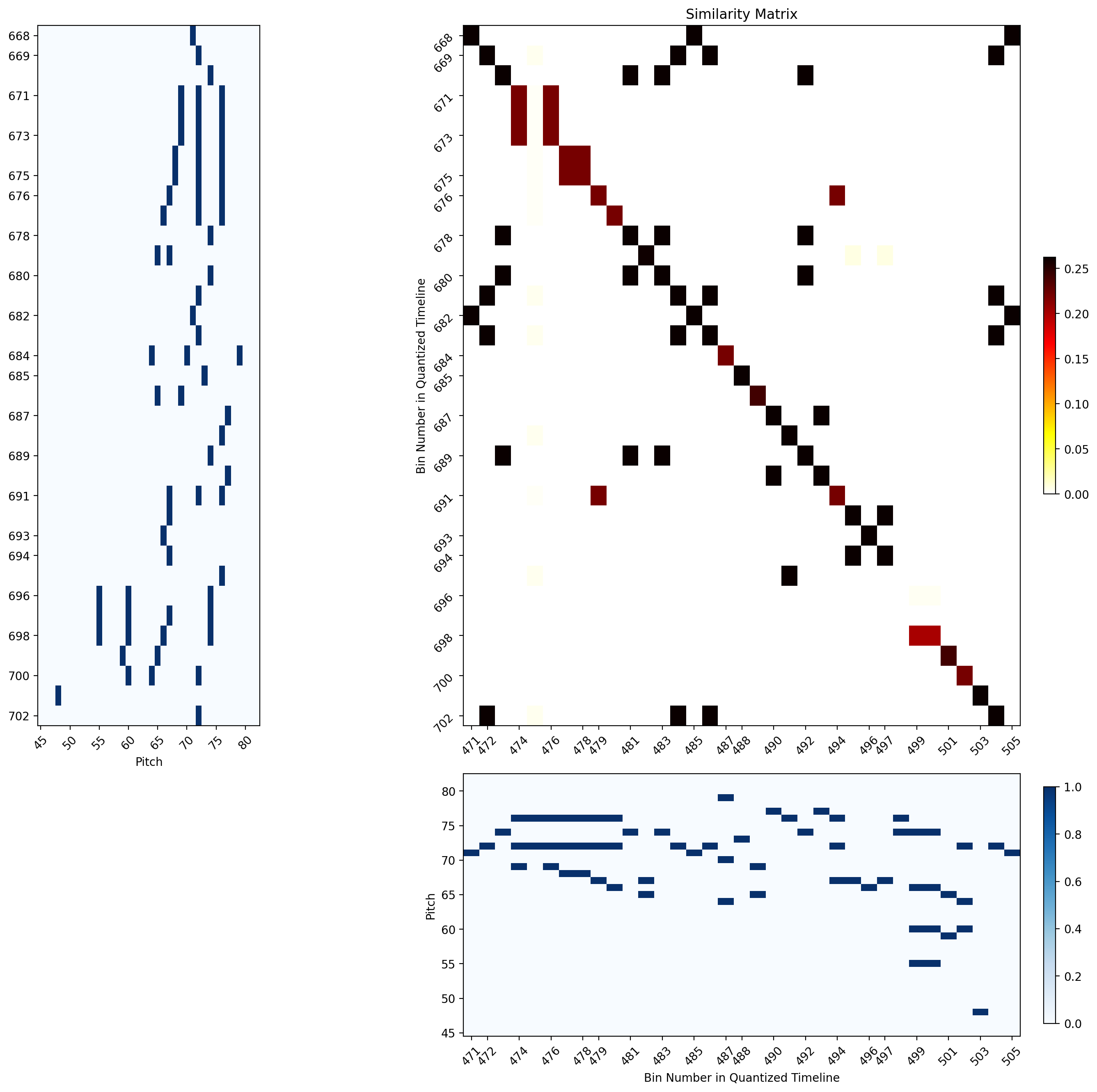 |
The tick indices reflect the bin numbers within the SSM of the whole rehearsal.
Walkthrough of the Rehearsal Structure Analysis Pipeline
Diagonal Finding:
The diagonals found at this phase are the only information passed from the SSM onto the subsequent pipeline phases. For the diagonal finding approach to pick all necessary diagonals for further grouping and filtering, our initial hypothesis is that there needs to be a balance between the following tradeoffs:
- Groups 1, 2, and 3 need shorter min_length settings
- Groups 4, 5, and 6 could rely on longer minimum length settings, although shorter settings could also help in identifying the smaller shifted diagonals for later grouping.
The light blue lines indicate the diagonals found using:
- minimum length = 10
- gap tolerance = 5 (gap tolerance must be less than min length)
- similarity threshold = 0.2
<a href=./Rehearsal_Structure_Analysis/figures/ponce_can/diagonalsearch_10_0-2_5.png">
 </a>
</a>
|

|
One way to understand the effectiveness of these settings is to see how the diagonals relate to the retrieval of group information. Below are the self similarity matrixes overlayed with interval information and the retrieved set of diagonals above. The intersection between the green horizontal and vertical rectangles represents the similarity matrix between 2 intervals of that group (for example, one of such intersections would a similarity matrix as shown for the intra-group fragment pairs above)

Group 1 |

Group 2 |
||||||||||||||||||||||||

Group 3 |

Group 4 |
||||||||||||||||||||||||

Group 5 |

Group 6 |
</table>
From the plots above we can see the following:
- As initially thought, this search does not yield enough diagonals in the intersecting boxes of the first 3 groups.
- For the last 3 groups it would be possible to postprocess this search meaningfully, although the recall is also not perfect.
In contrast, we use different settings and observe their effect:
- minimum length = 7
- gap tolerance = 4 (gap tolerance must be less than min length)
- similarity threshold = 0.15

|

|

Group 1 |

Group 2 |
||||||||||||||||

Group 3 |

Group 4 |
||||||||||||||||

Group 5 |

Group 6 |
</table>
There are several things to note:
- These settings mean that we want to retrieve diagonals of length 7 permitting up to 4 mismatches. This is too permissive to apply for certain types of compositions which would involve periodically repeating bins.
- Furthermore, despite being permissive settings, they still do not perfectly retrieve peaks in the intersections of groups 1, 2 and 3. However, this is likely the effect of grouping intervals that are variations of one another, where even in the case of perfect matches there would be variations between bins (let alone mistakes or repetitions).
- However, the short diagonals from these settings would allow some information pertaining to the first 3 groups to be passed to the next pipeline phases.
#### Grouping and Merging Diagonals (and Resulting Intervals)
As shown in the technical appendix, the found diagonals are grouped based on horizontal and vertical overlaps, followed by a final merging phase is simply to merge the horizontal and vertical groups based on overlapping diagonals.
- How can we use this group information to check the results.
|
params |
Median Diag. Length/Group |
Diag. Count per Group |
Inverval Results |
|
minimum length: 10, similarity threshold: 0.2, gap tolerance: 4, interval overlap ratio: 0.8 |

|

|
Results
|
|
minimum length: 7, similarity threshold: 0.15, gap tolerance: 4, interval overlap ratio: 0.8 |

|

|
Results
|
|
|
|
|
|